
Perceptron
Published:
![]()
MindNotes - Deep Learning - Basics
Author: Christian M.M. Frey
E-Mail: christianmaxmike@gmail.com
Perceptron
Class of Halfspaces
In the lecture, we have already discussed the hypothesis class of halfspaces. They are designed for binary classification problems, i.e., we have a design matrix $\mathcal{X} \in \mathbb{R}^d$ and a set of labels $\mathcal{Y}={-1, 1}$. The class of halfspaces is defined as follows:
\[HS_d = sign \circ L_d = \{x \mapsto sign(h_{w,b}(x)): h_{w,b} \in L_{d}\}\]with $h_{w,b}(x) = \langle w, x \rangle + b$, $b \in \mathbb{R}$ and $L_d$ being the class of affine functions $L_d = {h_{w,b}: w \in \mathbb{R}^d, b \in \mathbb{R}}$.
A convenient way is to incorporate the bias $b$ into $w$ as an extra coordinate and add an extra coordinate with a value of $1$ to all $x \in X$, i.e., $w’ = (b, w_1, w_2, \ldots, w_d) \in \mathbb{R}^{d+1}$ and $x’ = (1, x_1, x_2, \ldots, x_d) \in \mathbb{R}^{d+1}$
Perceptron
The activation function of the Perceptron is a sum of weighted inputs:
\[\sum_{j=1}^{M} w_j x_j\]The binary classification $y \in {-1, 1}$ is calculated as $\hat{y} = sign(h)$. The linear separating hyperplane is defined by $h(x) = 0$. The bias $b$ determines the class when all inputs are zero.
The Perceptron is an iterative algorithm that constructs a sequence of vectors $w^{(1)}, w^{(2)}, \ldots$. Initially, $w^{(1)}$ is set to be the all-zeros vector. At iteration $t$, the Perceptron finds an example $i$ that is mislabeled by $w^{t}$, namely, an example for which $sign(\langle w^{(t)}, x_i \rangle) \neq y_i$. Then, the perceptron updates $w^{t}$ by adding to it the instance $x_i$ scaled by the label $y_i$ and a learning parameter $\eta$.
Perceptron Learning rule
To learn a separating hyperplane, we need a learning rule to find optimal parameters for the weighting vector $w$ and the bias $b$. In the native perceptron learning rule, one presents randomly selected currently misslcassified patterns and adapts with only the current selected pattern. Let $x_t$ and $y_t$ be the training pattern in the $t$-th step. One adapts $t=1,2, \ldots$
\[w_{j} \leftarrow w_j + \eta y_t x_{t,j}\]A weight increases, when (postsynaptic) $y_t$ and (presynaptic) $x_{t,j}$ have the same sign; different signs lead to a weight decrease.
TASKS
- write a class $\textit{Perceptron}$
- in the init method, initialize variables necessary for the Perceptron model
- in the train(X,Y) method, we train the Perceptron according to the dataset and labels attached as parameters. If the number of iterations exceed a predefined maximal number of iterations, we say that the Perceptron could not identify a separating hyperplane. In each iteration, we check for misclassified datapoints, i.e., where $sign(\langle w^{(t)}, x_i \rangle) \neq y_i$ does not hold. If we have found a missclassified point, we adapt the weight vector $w$ according to the perceptron learning rule $w_{j} \leftarrow w_j + \eta y_t x_{t,j}$. If all points are classified correctly, the learning procedure is finished and the vector $w$ describes our weighting vector, our model.
# modules used in this assignment
import numpy as np
import random as rnd
import matplotlib.pyplot as plt
%matplotlib inline
class Perceptron(object):
"""
Perceptron Classifier.
Parameter
---------
eta : float
Learning rate (between 0..0 and 1.0)
max_iter : int
Passes (epochs) over the training set.
Attributes
---------
w : 1d-array
Weights after fitting.
eta: float
Learning rate
max_iter: int
maximal number of iterations
"""
def __init__(self, eta=.1, max_iter=1000):
self.max_iter = max_iter
self.w = []
self.eta = eta
def train (self, X, Y):
'''
Training method for data.
Parameters
----------
X : Training vectors
y : Target values
Returns
-------
bool : value indicating if a separating hyperplane could be found.
'''
no_examples, no_features = np.shape(X)
self.w = np.zeros (no_features)
for i in range(self.max_iter):
w_updated = False
for j in range(0, no_examples):
a = np.dot(self.w, X[j])
if np.sign(Y[j] * a) != 1:
w_updated = True
self.w += self.eta * Y[j] * X[j]
if not w_updated:
print("Convergence reached in %i iterations." % i)
return True
break
if w_updated:
print ("Convergence not reached in %i iterations." % self.max_iter)
return False
return w_updated
TASKS
Having defined our Perceptron and our learning procedure, we will use synthesized data to learn the model. Hence,
- define a procedure to create $n$ datapoints.
- Each datapoint $x_i$ has $dim$ features.
- To do so, we will define each feature to be selected randomly in the interval [-1,1]
def generate_data (n, dim):
'''
Generating training data.
Parameters
----------
n : the number of samples and 'n_features' is the
dim: number of features.
Returns
-------
X : training vectors
'''
X = np.zeros((n, dim+1))
for i in range(n):
pt = [rnd.uniform(-1,1) for d in range(dim)]
X[i] = [1] + pt
return X
X = generate_data(3,5)
print (X)
[[ 1. -0.3665874 0.85296486 0.91828138 0.19374553 0.33479028]
[ 1. -0.49043789 0.92317003 -0.81050984 -0.63240696 -0.67752993]
[ 1. 0.33602922 0.89392364 0.61747882 0.71009557 -0.60956841]]
TASKS
Let’s define a function to plot our dataset and linear separating hyplane in the two-dimensional case. As parameters, we attach the dataset, the labels and and instance of our learned perceptron model. With the labels at hand, we can use different markers for the two classes ${-1,1}$. (hint: use marker=”x” or marker=”o” to have dots or X as markers. If you want, you can in addition define different colors for the classes)
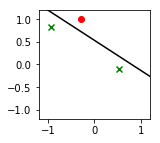
def plot2D(X, Y, p):
'''
Plots the data points and the separating hyperplane in the two dimensional case
Parameters
----------
X: matrix containing the data points
Y: label of the data points
p: instance of trained perceptron model
'''
Y_label_pos = (Y == 1)
plt.figure(figsize=(2,2))
plt.xlim((-1.2,1.2))
plt.ylim((-1.2,1.2))
plt.scatter(X[Y_label_pos,1],X[Y_label_pos,2], color="g", marker="x")
plt.scatter(X[~Y_label_pos,1],X[~Y_label_pos,2], color="r")
xmin = -1.2
xmax = 1.2
w = p.w
a = -w[1] / w[2]
xx = np.linspace(xmin, xmax)
yy = a * xx - w[0] / w[2]
plt.plot(xx, yy, 'k-')
# number of training data
n=3
# generate data
X = generate_data(n, 2)
# labeling for data
Y = np.array([1.,-1.,1.])
# initialize and train Perceptron
p = Perceptron()
p.train(X,Y)
# plot it!
plot2D(X,Y,p)
Convergence reached in 5 iterations.
References and further reading:
- Shai Shalev-Shwartz, Shai Ben-David. Understanding Machine Learning: From Theory to Algorithms. Cambridge University Press